

jeudi 14 février 2013
dimanche 10 février 2013
Open Source SOA on Talend
IT departments have held an application-centric view of the world.
Most of their budgets have been allocated to the purchase, deployment, and maintenance of individual applications. In more recent times, a growing percentage of the budget has been allocated to integration projects in an attempt to deliver broader and more seamless support for business processes. However, these projects have often fallen short of their promise due to the inherent rigidity of hardwired integration: any change to a single application must be propagated across the entire integration, creating an expensive and change-averse infrastructure.
Open source SOA on Talend enables IT departments to make the transition from an application-centric view of the world to a process centric one. IT departments now have the freedom to combine business services from multiple applications to deliver true end-to-end support for business processes. IT can upgrade or change applications without impacting other applications in the SOA by utilizing integration mechanisms such as Web services.
Open source SOA on Talend enables IT departments to make the transition from an application-centric view of the world to a process centric one. IT departments now have the freedom to combine business services from multiple applications to deliver true end-to-end support for business processes. IT can upgrade or change applications without impacting other applications in the SOA by utilizing integration mechanisms such as Web services.
dimanche 28 février 2010
samedi 27 février 2010
PG SCHEMA
http://www.mail-archive.com/postgis-users@postgis.refractions.net/msg02169.html
http://www.paolocorti.net/2008/01/30/installing-postgis-on-ubuntu/
http://postgis.refractions.net/pipermail/postgis-users/2007-April/015206.html
http://www.paolocorti.net/2008/01/30/installing-postgis-on-ubuntu/
http://postgis.refractions.net/pipermail/postgis-users/2007-April/015206.html
lundi 22 février 2010
Enabling Remote Access pgsql
If you wish to enable remote access, modify the cluster settings. The configuration files for each cluster are in the directory /etc/postgresql/version/clustername/, e.g. /etc/postgresql/8.1/main/.
Edit the file postgresql.conf, and remove the comment marker on the line for the listen_addresses setting, so that it reads:
This enables md5 authentication, which means that login roles are secured with passwords that PostgreSQL itself stores in an encrypted form, and that PostgreSQL will require a valid password for any remote connection to use a role. After you make this change, ident authentication remains enabled for local logins.
You may, of course, change the local line in pg_hba.conf to disable ident authentication. Make sure that you can actually login to your PostgreSQL cluster with the postgres role and a password first!
To make your changes take effect, restart the service:
By default, the postgres system account on Debian is locked, and you should not unlock it. Cracking tools now try to use postgres, root, and other well-known system account names when they attempt to gain access to UNIX-like operating systems.
Under no circumstance should you enable PostgreSQL ident authentication for any remote access. The ident system cannot safely verify or guarantee the identity of any user on a remote system.
Edit the file postgresql.conf, and remove the comment marker on the line for the listen_addresses setting, so that it reads:
listen_addresses = '*'# nano /etc/postgresql/8.1/main/pg_hba.confhost all all 192.168.1.0/24 md5This enables md5 authentication, which means that login roles are secured with passwords that PostgreSQL itself stores in an encrypted form, and that PostgreSQL will require a valid password for any remote connection to use a role. After you make this change, ident authentication remains enabled for local logins.
You may, of course, change the local line in pg_hba.conf to disable ident authentication. Make sure that you can actually login to your PostgreSQL cluster with the postgres role and a password first!
To make your changes take effect, restart the service:
# /etc/init.d/postgresql-8.1 restartBy default, the postgres system account on Debian is locked, and you should not unlock it. Cracking tools now try to use postgres, root, and other well-known system account names when they attempt to gain access to UNIX-like operating systems.
Under no circumstance should you enable PostgreSQL ident authentication for any remote access. The ident system cannot safely verify or guarantee the identity of any user on a remote system.
jeudi 18 février 2010
Apache2 et proxypass
On se connecte sous root.
On commence par installer apache
apt-get install apache2
On active le mode proxy et les dépendances nécessaires, puis on recharge :
a2enmod proxy
a2enmod proxy_http
a2enmod proxy_connect
/etc/initd/apache2 force-reload
On ouvre les permissions sur notre domaine
nano /etc/apache2/mods-enabled/proxy.conf
Allow from nc.run
On commence par installer apache
apt-get install apache2
On active le mode proxy et les dépendances nécessaires, puis on recharge :
a2enmod proxy
a2enmod proxy_http
a2enmod proxy_connect
/etc/initd/apache2 force-reload
On ouvre les permissions sur notre domaine
nano /etc/apache2/mods-enabled/proxy.conf
Allow from nc.run
mercredi 10 février 2010
PostGIS in Action is the first book devoted entirely to PostGIS. It will help both new and experienced users write spatial queries to solve real-world problems. For those with experience in more traditional relational databases, this book provides a background in vector-based GIS so you can quickly move to analyzing, viewing, and mapping data. Advanced users will learn how to optimize queries for maximum speed, simplify geometries for greater efficiency, and create custom functions suited specifically to their applications. It also discusses the new features available in PostgreSQL 8.4 and provides tutorials on using additional open source GIS tools in conjunction with PostGIS.


mardi 9 février 2010
PuTTY for SSH Tunneling to PostgreSQL Server
What SSH Tunneling allows you to do is to tunnel all your traffic to the server thru your SSH connection. It is basically a Virtual Private Network (VPN) using SSH. The basic idea is you map local ports on your pc to remote service ports on the server. When you launch your SSH session, you can then connect with any application e.g. PgAdmin III, MS Access whatever to this remote port via the local port. Instead of specifying the remote server port when setting up your PgAdmin III or MS Access connection, you specify the ip as localhost and port as whatever port you configured to receive traffic via the Tunnel.
For more info clik here
For more info clik here
jeudi 28 janvier 2010
Linux: Iptables Allow PostgreSQL server incoming request

Open port 5432
By default PostgreSQLt listen on TCP port 5432. Use the following iptables rules allows incoming client request (open port 5432) for server IP address 202.54.1.20 :iptables -A INPUT -p tcp -s 0/0 --sport 1024:65535 -d 202.54.1.20 --dport 5432 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -s 202.54.1.20 --sport 5432 -d 0/0 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPTAs posted earlier, you do not wish give access to everyone. For example in web hosting company or in your own development center, you need to gives access to POSTGRES database server from web server only. Following example allows POSTGRES database server access (202.54.1.20) from Apache web server (202.54.1.50) only:
iptables -A INPUT -p tcp -s 202.54.1.50 --sport 1024:65535 -d 202.54.1.20 --dport 5432 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -s 202.54.1.20 --sport 5432 -d 202.54.1.50 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPTAllow outgoing POSTGRES client request (made via postgresql command line client or perl/php script), from firewall host 202.54.1.20:
iptables -A OUTPUT -p tcp -s 202.54.1.20 --sport 1024:65535 -d 0/0 --dport 5432 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A INPUT -p tcp -s 0/0 --sport 5432 -d 202.54.1.20 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPT
How Do I Enable remote access to PostgreSQL database server?
How Do I Enable remote access to PostgreSQL database server?
Step # 1: Login over ssh if server is outside your IDC
Login over ssh to remote PostgreSQL database server:$ ssh user@remote.pgsql.server.comStep # 2: Enable client authentication
Once connected, you need edit the PostgreSQL configuration file, edit the PostgreSQL configuration file /var/lib/pgsql/data/pg_hba.conf (or /etc/postgresql/8.2/main/pg_hba.conf for latest 8.2 version) using a text editor such as vi.Login as postgres user using su / sudo command, enter:
$ su - postgresEdit the file:
$ vi /var/lib/pgsql/data/pg_hba.confOR
$ vi /etc/postgresql/8.2/main/pg_hba.confAppend the following configuration lines to give access to 10.10.29.0/24 network:
host all all 10.10.29.0/24 trustSave and close the file. Make sure you replace 10.10.29.0/24 with actual network IP address range of the clients system in your own network.
Step # 2: Enable networking for PostgreSQL
You need to enable TCP / IP networking. Use either step #3 or #3a as per your PostgreSQL database server version.Step # 3: Allow TCP/IP socket
If you are using PostgreSQL version 8.x or newer use the following instructions or skip to Step # 3a for older version (7.x or older).You need to open PostgreSQL configuration file /var/lib/pgsql/data/postgresql.conf or /etc/postgresql/8.2/main/postgresql.conf.
# vi /etc/postgresql/8.2/main/postgresql.confOR
# vi /var/lib/pgsql/data/postgresql.conf Find configuration line that read as follows:
listen_addresses='localhost'Next set IP address(es) to listen on; you can use comma-separated list of addresses; defaults to 'localhost', and '*' is all ip address:
listen_addresses='*'Or just bind to 202.54.1.2 and 202.54.1.3 IP address
listen_addresses='202.54.1.2 202.54.1.3'Save and close the file. Skip to step # 4.
Step #3a - Information for old version 7.x or older
Following configuration only required for PostgreSQL version 7.x or older. Open config file, enter:# vi /var/lib/pgsql/data/postgresql.conf Bind and open TCP/IP port by setting tcpip_socket to true. Set / modify tcpip_socket to true:
tcpip_socket = trueSave and close the file.
Step # 4: Restart PostgreSQL Server
Type the following command:# /etc/init.d/postgresql restartStep # 5: Iptables firewall rules
Make sure iptables is not blocking communication, open port 5432 (append rules to your iptables scripts or file /etc/sysconfig/iptables):iptables -A INPUT -p tcp -s 0/0 --sport 1024:65535 -d 10.10.29.50 --dport 5432 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -s 10.10.29.50 --sport 5432 -d 0/0 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPTRestart firewall:
# /etc/init.d/iptables restartStep # 6: Test your setup
Use psql command from client system. Connect to remote server using IP address 10.10.29.50 and login using vivek username and sales database, enter:$ psql -h 10.10.29.50 -U mbb -d sales PgAdmin NT:The service field specifies parameters to control the database service process. Its meaning is operating system dependent.
If pgAdmin is running on a Windows machine, it can control the postmaster service if you have enough access rights. Enter the name of the service. In case of a remote server, it must be prepended by the machine name (e.g. PSE1\pgsql-8.0). pgAdmin will automatically discover services running on your local machine.
mercredi 20 janvier 2010
PostGIS: Update geometry_columns table
If you add or remove tables with geometry columns, the geometry_columns table isn't updated automatically. To update the geometry_columns table try:
SELECT probe_geometry_columns();
template-postgis database
Create a template_postgis database
Some might find this useful for creating PostGIS databases without having to be PostgreSQL
super users. The idea is to create a template_postgis database, install plpgsql and postgis into
it, and then use this database as a template when creating new PostGIS databases.
Now non-super users can create PostGIS databases using template_postgis:
postgres=# CREATE DATABASE corolle_db WITH OWNER=corolle TEMPLATE= template_postgis ;
Some might find this useful for creating PostGIS databases without having to be PostgreSQL
super users. The idea is to create a template_postgis database, install plpgsql and postgis into
it, and then use this database as a template when creating new PostGIS databases.
$ psql template1 \c template1 CREATE DATABASE template_postgis WITH TEMPLATE = template1 ENCODING = 'LATIN1'; -- next set the 'datistemplate' record in the 'pg_database' table for -- 'template_postgis' to TRUE indicating its a template UPDATE pg_database SET datistemplate = TRUE WHERE datname = 'template_postgis'; \c template_postgis CREATE LANGUAGE plpgsql; \i /usr/share/postgresql/contrib/lwpostgis.sql; \i /usr/share/postgresql/contrib/spatial_ref_sys.sql; -- windows -- C:\Program Files\PostgreSQL\8.2\share\contrib\lwpostgis.sql -- C:\Program Files\PostgreSQL\8.2\share\contrib\spatial_ref_sys.sql GRANT ALL ON geometry_columns TO PUBLIC; GRANT ALL ON spatial_ref_sys TO PUBLIC; -- vacuum freeze: it will guarantee that all rows in the database are -- "frozen" and will not be subject to transaction ID wraparound -- problems. VACUUM FREEZE;
postgres=# CREATE DATABASE corolle_db WITH OWNER=corolle TEMPLATE= template_postgis ;
HOWTO PostgreSQL
Les fichiers de configuration de trouvent dans $HOME/data et notamment pg_hba.cong pour le gestion des droits et postgresql.conf pour la configuration générale du service. Sous Debian/UBUNTU ces fichiers sont des liens symboliques vers des fichiers se trouvant dans /etc/postgresql/
Voici un exemple simple de fichier data/pg_hba.conf qui règle certaines permissions :
La première chose à faire est de mettre un mot de passe à l'admin postgres :
On crée un utilisateur :
Pour supprimer une base de données :
Voici les différents types de données pour les champs d'une table :
claSiQuaL, la syntaxe :
Insertion de données
Insertion de tous les champs d'une table :
Extraction de données
Rien ne vaut des exemples :
Ainsi la requête suivante est fausse :
Mise à jour des données
Toujours avec un exemple :
Encore avec un exemple :
Pour sauvegarder une base de données :
Liens
Documentation officielle
http://www.postgresql.org/docs/7.4/interactive/tutorial.html
Voici un exemple simple de fichier data/pg_hba.conf qui règle certaines permissions :
host all all 192.168.0.2 255.255.255.255 password host all all 1.2.3.4 255.255.255.255 password local all postgres ident sameuser local all all password host all all 127.0.0.1 255.255.255.255 password host all all 0.0.0.0 0.0.0.0 rejectSous Debian/UBUNTU, les journaux de PosgreSQL se trouvent dans /var/log/postgresql/postgresql.log
La première chose à faire est de mettre un mot de passe à l'admin postgres :
# su postgres $ psql -d template1 template1=# alter user postgres with password 'MDP';Puis éditer data/pg_hba.conf et mettre une ligne ressemblant à :
local all postgres passwordEnsuite pour gérer une base de données.
On crée un utilisateur :
$ createuser login -P -D -APuis on crée une base de données "pour" cet utilisateur :
$ createdb -O login -E LATIN1 baseOn prendra bien garde à l'encodage de la table : LATIN9, LATIN1, UNICODE, etc.
Pour supprimer une base de données :
$ dropdb basePour supprimer un utilisateur :
$ dropuser loginPour lister les base de données :
$ psql -lOn peut maintenant "utiliser" notre base de données avec le client en ligne PostgreSQL en ligne de commande :
$ psql base login ma_base=#Voici quelques commandes pratiques à retenir :
\d [NAME] describe table, index, sequence, or view
\d{t|i|s|v|S} [PATTERN] (add "+" for more detail)
list tables/indexes/sequences/views/system tables
\da [PATTERN] list aggregate functions
\db [PATTERN] list tablespaces (add "+" for more detail)
\dc [PATTERN] list conversions
\dC list casts
\dd [PATTERN] show comment for object
\dD [PATTERN] list domains
\df [PATTERN] list functions (add "+" for more detail)
\dg [PATTERN] list groups
\dn [PATTERN] list schemas (add "+" for more detail)
\do [NAME] list operators
\dl list large objects, same as \lo_list
\dp [PATTERN] list table, view, and sequence access privileges
\dT [PATTERN] list data types (add "+" for more detail)
\du [PATTERN] list users
\l list all databases (add "+" for more detail)
\z [PATTERN] list table, view, and sequence access privileges (same as \dp)
\q = quitter
\h = aide
SELECT version(); = version PostgreSQL
SELECT current_date; = date actuelle
\i fichier.sql = lit les instructions du fichier fichier.sql
\d table = décrit une table (comme DESCRIBE avec MySQL)Création de tableVoici les différents types de données pour les champs d'une table :
char(n) varchar(n) int real double precision date time timestamp intervalRemarque : on peut aussi définir ses propres types de données
claSiQuaL, la syntaxe :
CREATE TABLE ma_table (col1 type, [...], coln type); DROP TABLE ma_table;Pour la forme un petit exemple tiré de la doc de PostgreSQL :
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- low temperature
temp_hi int, -- high temperature
prcp real, -- precipitation
date date
);Rq : deux tirets -- introduisent des commentaires...Insertion de données
Insertion de tous les champs d'une table :
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');Insertion en précisant les champs : INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');Insertion à partir d'un fichier externe : COPY weather FROM '/home/user/weather.txt';Rq : voir www.postgresql.org/docs/7.4/interactive/sql-copy.html
Extraction de données
Rien ne vaut des exemples :
SELECT * FROM weather; SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather; SELECT * FROM weatherWHERE city = 'San Francisco' AND prcp > 0.0; SELECT DISTINCT city FROM weather ORDER BY city;Avec des jointures :
SELECT * FROM weather, cities WHERE city = name; SELECT weather.city, weather.temp_lo, cities.location FROM weather, cities WHERE cities.name = weather.city; SELECT * FROM weather INNER JOIN cities ON (weather.city = cities.name); SELECT * FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name); SELECT * FROM weather w, cities c WHERE w.city = c.name;Avec des fonctions (Aggregate Functions) :
SELECT max(temp_lo) FROM weather;Attention, les "Aggregate Functions" ne peuvent être utilsées dans la clause WHERE
Ainsi la requête suivante est fausse :
SELECT city FROM weather WHERE temp_lo = max(temp_lo);On devra donc faire :
SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);On pourra bien sûr utilise "GROUP BY ...", "HAVING ...", etc.
Mise à jour des données
Toujours avec un exemple :
UPDATE weather SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2 WHERE date > '1994-11-28';Suppression des données
Encore avec un exemple :
DELETE FROM weather WHERE city = 'Hayward';Pour effacer toutes les données d'une table :
DELETE FROM weather;PostgreSQL et les sauvegardes
Pour sauvegarder une base de données :
$ pg_dump NOM_BASE > NOM_FICHIERPour restaurer une base de données :
$ createdb -O login -E LATIN1 newbase psql newbase < NOM_FICHIERSauvegarder une base complète :
$ pg_dumpall > NOM_FICHIERRq : Attention, il y a certaines limitations dans la sauvegarde "à chaud". Voir http://traduc.postgresqlfr.org/pgsql-fr/backup.html
Liens
Documentation officielle
http://www.postgresql.org/docs/7.4/interactive/tutorial.html
Les Roles PostgreSQL
ALTER ROLE nom [ [ WITH ] option [ ... ] ]
où option peut être :
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| CREATEUSER | NOCREATEUSER
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| CONNECTION LIMIT limiteconnexion
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'motdepasse'
| VALID UNTIL 'dateheure'
ALTER ROLE nom RENAME TO nouveaunom
ALTER ROLE nom SET parametre_configuration { TO | = } { valeur | DEFAULT }
ALTER ROLE nom RESET parametre_configuration
mardi 19 janvier 2010
PostgreSQL-postgis Installation avec QGIS et Pgadmin3
1-Utilisation de finger pour plus d'informations sur les utilisateurs.



Do the same with the other 3 sqls generated from the previous step:
finger postgres
-Création d'utilisateur postgres:$ sudo -s -u postgres Password:
Aprés:
$sudo -s
entrez la mot de passe root
aprés
$ su postgres
$psql
Pour avoir l'interface interactive de PostgreSQL.
création de user et de rôle:
$ createuser -P
ainsi, le programme vous demanderas naturellement 2 fois votre mot pass.
création de la base: $ createdb -O-E UTF8
Ajouter la mot de passe:
psql -d postgres -c "ALTER USER postgres WITH PASSWORD 'mot_de_passe';"
Reboot PostgreSQL
$ sudo /etc/init.d/postgresql-8.4 restart
Ensuite, on peut se connecter via :
$ psql -UMot de passe pour l'utilisateur :
Par raisons de securité dans postgreSQL il faut impirativement ajouter des rôles utilisateur ( NOSUPERUSER) et (LOGIN)
Recap:

Lancez PgAdmin3:
remplissez les champs concernées:
Login, Mot de passe,base, nom de la connection, param de securité,Hôte et base de maintenace (template1).
6 details.
Pour QGIS il faut installer des tables géometriques tous dabord pour pouvoir se connecter à la base correctement.
Le mieux c'est de créer un database avec le template mentionnées si dessus.
Aprés il reste que d'injecter des shp dans le postgis databse .

Qgis:
1-Importer des shapes dans PostgreSQL.
2-Attention au codage de caractéres (pb).
3-Ajouter une couche postgis.
NB:il faut confirmer la connection à la base à chaque fois.

Enjoy, you can edit on WYSIWYG mode the postgis database also.
Manual Data Loading with
$ shp2pgsql -I -s 32633 POI.shp gis_schema.poi > poi.sql Shapefile type: Point Postgis type: POINT[2] $ shp2pgsql -I -s 32633 vestizioni.shp gis_schema.vestizioni > vestizioni.sql Shapefile type: Arc Postgis type: MULTILINESTRING[2] $ shp2pgsql -I -s 32633 compfun.shp gis_schema.compfun > compfun.sql Shapefile type: Polygon Postgis type: MULTIPOLYGON[2] $ shp2pgsql -I -s 32633 zone.shp gis_schema.zone > zone.sql Shapefile type: Polygon Postgis type: MULTIPOLYGON[2]
Note that we used 2 options of the shp2pgsql: -I will also create a GiST index on the geometry column -s will give to PostGIS the information of the srid of the data (srid=32633 is for gis data with a spatial reference WGS84, UTM 33 N)Now it is time to execute the *.sql scripts with the gis user:
$ psql -d gisdb -h localhost -U gis -f poi.sql
BEGIN
psql:poi.sql:4: NOTICE: CREATE TABLE will create implicit sequence "poi_gid_seq" for serial column "poi.gid"
psql:poi.sql:4: NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "poi_pkey" for table "poi"
CREATE TABLE
addgeometrycolumn
------------------------------------------------------
gis_schema.poi.the_geom SRID:32633 TYPE:POINT DIMS:2
(1 row)
CREATE INDEX
COMMIT$ psql -d gisdb -h localhost -U gis -f compfun.sql $ psql -d gisdb -h localhost -U gis -f vestizioni.sql $ psql -d gisdb -h localhost -U gis -f zone.sql
mercredi 13 janvier 2010
Spatial OLAP
Notre sauce c'est l'open source spatial, ça fait long temps que je cherche à créer un datawarehouse Spatial sous postgis, j'ai trouvé des bonnes outils open source qui ferais bien ça ( PostGeoOLAP+JUMP+ROLAP)
"Spatial OLAP can be defined as a visual platform built especially to support rapid and easy spatiotemporal analysis and exploration of data following a multidimensional approach comprised of aggregation levels available in cartographic displays as well as in tabular and diagram displays." Bédard, 1997.
Concepts:
http://spatialolap.scg.ulaval.ca/concepts.asp
lundi 11 janvier 2010
Create GIST Index for PostgreSQL/Postgis
PostgreSQL/Postgis can't update automatically her spatial reference system for
updating PostgreSQL/Postgis table You can proceed for all the tables which have Geometry collumns.
A script named 'createGISTIndex.sql' is provided in the 'SQL' dir in the Gisgraphy distribution to create all the GIST indexes for all the tables and this can be a good exemple.
updating PostgreSQL/Postgis table You can proceed for all the tables which have Geometry collumns.
A script named 'createGISTIndex.sql' is provided in the 'SQL' dir in the Gisgraphy distribution to create all the GIST indexes for all the tables and this can be a good exemple.
- usage : psql -UYOURUSER -h 127.0.0.1 -d gisgraphy -f /path/to/file/createGISTIndex.sql \connect gisgraphy \echo will create all the index needed by gisgraphy to improve performance,
\this make take a while depends on how many data are in database \echo will create Geonames Index CREATE INDEX locationIndexAdm ON adm USING GIST (location); CREATE INDEX locationIndexAirport ON airport USING GIST (location); CREATE INDEX locationIndexAmusePark ON amusePark USING GIST (location); CREATE INDEX locationIndexAqueduc ON quay USING GIST (location);
..
..
VACUUM FULL ANALYZE;
mercredi 30 décembre 2009
Geocoding Adresses
# Pieces of script to geocode addresses file with geopy: the reference web services is geonames (baroudi.malek@gmail.com)
#Need geopy installation
#Need python-beautifulsoup installation
#The output file is csv
import urllib2
import os
import csv
from geopy import geocoders
host="proxy......"
port="8080"
proxy_user = '...'
proxy_password_orig='...'
proxy_password = urllib2.quote(proxy_password_orig, "")
proxy_url = 'http://' + proxy_user + ':' + proxy_password + '@' + host+ ':' + port
proxy_support = urllib2.ProxyHandler({"http":proxy_url})
opener = urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
f = urllib2.urlopen('http://www.python.org/')
print f.headers
reader = csv.reader(open('adresses.csv', "rb"), dialect="excel",quotechar="'", delimiter=";")
# Get addresses and names from csv file
# 1st column: address / 2nd column: name
myResult=[]
gn = geocoders.GeoNames()
myCmpt=0
for myRecord in reader:
myName=myRecord[1]
addr=myRecord[0]
myName, (lat, lng) = gn.geocode(addr)
dataToSave="%s: %.5f, %.5f" % (myName, lat, lng)
myResult.append(dataToSave)
print "%s: %.5f, %.5f" % (myName, lat, lng)
writer = csv.writer(open("geoResult.csv", "wb"),quotechar=" ", delimiter="\n")
writer.writerows([myResult])
#The result is like here:
[1723] lat : 48.477307000000003, long : 7.2176159999999996, - RUE DE L'EGLISE
[1724] lat : 48.562179999999998, long : 7.6772330000000002, - RUE DES FLANDRES
#Need geopy installation
#Need python-beautifulsoup installation
#The output file is csv
import urllib2
import os
import csv
from geopy import geocoders
host="proxy......"
port="8080"
proxy_user = '...'
proxy_password_orig='...'
proxy_password = urllib2.quote(proxy_password_orig, "")
proxy_url = 'http://' + proxy_user + ':' + proxy_password + '@' + host+ ':' + port
proxy_support = urllib2.ProxyHandler({"http":proxy_url})
opener = urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
f = urllib2.urlopen('http://www.python.org/')
print f.headers
reader = csv.reader(open('adresses.csv', "rb"), dialect="excel",quotechar="'", delimiter=";")
# Get addresses and names from csv file
# 1st column: address / 2nd column: name
myResult=[]
gn = geocoders.GeoNames()
myCmpt=0
for myRecord in reader:
myName=myRecord[1]
addr=myRecord[0]
myName, (lat, lng) = gn.geocode(addr)
dataToSave="%s: %.5f, %.5f" % (myName, lat, lng)
myResult.append(dataToSave)
print "%s: %.5f, %.5f" % (myName, lat, lng)
writer = csv.writer(open("geoResult.csv", "wb"),quotechar=" ", delimiter="\n")
writer.writerows([myResult])
#The result is like here:
[1723] lat : 48.477307000000003, long : 7.2176159999999996, - RUE DE L'EGLISE
[1724] lat : 48.562179999999998, long : 7.6772330000000002, - RUE DES FLANDRES
dimanche 5 avril 2009
How to become a better Java Developer?
http://kvrlogs.blogspot.com/2006/04/how-to-become-java-developer.html
mardi 31 mars 2009
Les ETL Spatiales
présentation
Il existe deux technologies complémentaires dans le domaine de traitements de données géographique et spatiales, les Systèmes d'information géographiques (SIG) qui sont les outils de traitement de données géographiques et les ETL spatiales qui publies et rends les données disponibles pour un "SIG".
Bien que les SIG existaient depuis plusieurs décennies, l'outils ETL n'a vue l'âge que maintenant en raison de volume importants de données géographiques qui les recueillies et les distribuent sous plusieurs formats concernés.
Les besoins d'utiliser un système d'information géographique dans les entreprises augmentent de plus en plus ce qui accélère l'utilisation de SIG par les spécialistes de grands projets de développement et d'aide à la décision.
Afin que les SIG peuvent effectivement utiliser des données et toutefois ils doivent êtres intéroperables avec ces données,l'interopérabilités qui peut être réalisée soit par transformation format-à-format ou par lecture directe,cependant le rôle de l'outil ETL spatiale est de mettre en disposition les données aux applications SIG.
Pour mieux comprendre le rôle inter-complémentaire de ces deux technologies, nous devons examiner le monde non-spatiales de systèmes d'information et management d'entreprise (SIM) et le rôle qui joue l' ETL dans ce domaine.
Qu'est ce que un ETL ?
ETL est l'acronyme de « Extract-Transforme-Load ».
Un ETL permet l'extraction, la transformation et le chargement de données depuis des sources diverses (Base de données,Fichiers,Flux,Webservice) vers des cibles préalablement définies par l'utilisateur.
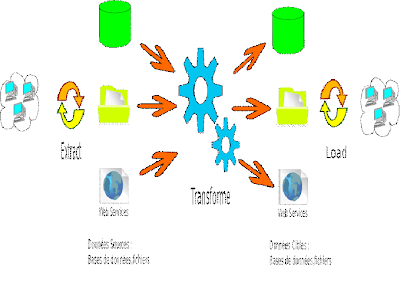
De nombreux systémes de gestion de base de données sont supportés nativement en lecture/écriture (Oracle,Postgres/SQL,Ms Sql Server,DB,Mysql,.......).
De nombreux types de fichiers aussi peuvent egalement être lus ou écrits : Csv,EXEL,Txt,Xml,.....
Notons que la plupart des ETL disposent d'une interface graphique permettant l'élaboration des différents scénarios d'intégration.
Les rôles des Intégrateurs est ainsi quasiment facilitées,tant au niveau de la conception que de la l'intégration de traitement de données.
Bien que les ETL pour les traitements non-spatiales de données existent depuis un certain temps, l'outils ETL capables de gérer les caractéristiques des données spatiales a seulement apparu au début des années 1990.
Qu'est ce que un ETL Spatial?
les ETL Spatiales ont vue le jour dans l'industrie de SIG pour permettre l'interopérabilité (ou l'échange d'informations) dans l'industrie du large éventail d'applications de cartographie et des formats propriétaires. Toutefois, les ETL Spatiales sont également en train de devenir de plus en plus utilisée dans le domaine de systèmes d'information géographique et de management d'entreprise ainsi que pour aider a l'organisation et à l'intégreration des données spatiales et non spatiales, voire aussi le développement de la compétitivité stratégique d'affaires des ces
entreprises.
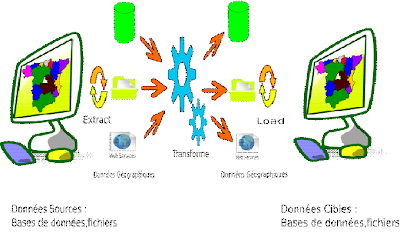
Traditionnellement, les applications a base de SIG ont des capacités de lire ou d'importer un nombre limité de formats de données spatiales, avec des librairies spécialisée dans la transformation des données,ou leurs concept est d'importer les données puis d'effectuer étape par étape de transformation et d'analyse dans l'application SIG lui-même, en revanche, l'ETL Spatial ne nécessite pas d'importer ou d'afficher les données seulement mais généralement de s'acquitter de ses tâches dans un unique processus d'extraction,transformation et chargement préalablement définis.
Avec les efforts visant à une plus grande interopérabilité au sein de l'industrie des SIG, de nombreuses applications SIG sont désormais intégrer des outils ETL spatiale au sein de leurs produits,notons l'interopérabilité des données par l'extension FME d' ArcGIS qui est un bon exemple de cela.
A quels usages et à quels utilisateurs répond un ETL spatial ?
1.Usages
Un ETL spatiale a un certain nombre d'utilisations qui est en faite:
- Nettoyage de données: L'élimination des erreurs dans un jeu de données.
- Fusion de données: Le regroupement de plusieurs jeux de données dans un cadre commun
le «common framework - Conflation» ou bien l'acte de combiner deux cartes dans une nouvelle carte qui est généralement effectué par l'enregistrement d'une zone de chevauchement entre le deux cartes est un bon exemple de celui la.
- Vérification des données: La comparaison de plusieurs jeux de données pour la vérification et l'assurance de qualité.
- La traduction de données: La conversion des données spatiales d'un format à un autre sans changement de structure ou de schéma.
2.Utilisations
Les ETL spatiales peuvent être utilisées dans plusieurs domaine d'organisation dans laquelle l'information géographique est une élément crucial de système d'information.
* Gouvernement
Les options sont pratiquement illimitées pour les gouvernements où la technologie spatiale permet a l'accès, le partage et la visualisation des données relatives aux personnes, lieux et services administratives.
L'analyse spatiale joue un rôle critique dans des domaines tels que la sécurité publique, développement économique, registres fonciers, les services de santé, la sécurité,la défense et le renseignement.
*Assurances
Le secteur des assurances profite de données spatiales. Par exemple, pour traiter les revendications, d'analyse spatiale, qui permet les réclamations pour localiser les transformateurs et les créances clients, de visualiser les zones de dommages, et de créer des cartes incident frontière.
Pour la souscription, les compagnies d'assurance utilisent l'analyse spatiale pour décider quels risques à assurer et à quel taux par l'identification des domaines de pointe potentiel de perte, de la cartographie historique des modes de revendications et de la segmentation à haut risque politiques, par région géographique.
*Institutions Financières
La technologie SIG offre un aperçu aux institutions financières sur leurs clients d'achat fidéles, les comportements financiers, et les besoins d'autres produits ou services qui lui ont permis de cibler leurs meilleures perspectives.
Les institutions financières utilisation des données spatiales pour la prospection du site pour déterminer l'emplacement des nouvelles succursales de banques et des guichets automatiques ainsi pour traiter les règlements fédéraux comme la loyauté des prêts au sein de la branche des zones où des données spatiales par la suite ils peuvent afficher la répartition des titulaires de comptes en ce qui concerne les entourant la démographie et la situation économique.
*Télécommunications/Location-Based Services (LBS)
Les Solutions ETL Spatiales fournis une technologie stratégique essentielle pour de nombreux fournisseurs d'information. Par exemple, les prestataires peuvent intégrer leurs données spatiales aux entreprises pour permettre aux personnelles d'avoir des informations d'assistance a distant , via téléphones cellulaires ou ordinateurs portables pour trouver les magasins ciblés et effectuer rapidement le suivi de produits, la numérisation et d'autres « Location Based Services »,exemple : les centres d'appels d'urgence qui alerte les centres de service d'accidents avec les endroits approprié au mieux d'intervenir rapidement et efficacement.
Système d' Informations Management et ETL
Avec l'augmentation de niveau d'utilisation de système d'informations et Management d'entreprise, les ETL ont connue la vie par les matures producteurs de « Business Intelligence » comme Informatica,Peravasive software,IBM,Oracle et Talend, ces outils donnent énormément d'avantages au système d'information et management d'entreprise.
Cependant avec cette analogie promu par ces canaux d'informations la connection de deux systèmes peuvent être bien assurée.
*Transformations de formats
ces canaux d'information sont utilisée pour changer les données d'une ou plusieurs formats d'un entrepôt de données source à une ou plusieurs formats d'un entrepôt de données destinations.
Ces entrepôts sont des jeux de données dans un système et une forme particulière.
Une fois l'entrepôt de données destination est remplis, le système sera accomplis.
*Accès directe
Ces canaux d'information sont utilisées pour la traduction directe d'une ou plusieurs données d'un entrepôts de données sources vers une ou plusieurs autres données d'un entrepôts de données destinations et dont il y' on a besoin.
Avec ces deux modes préalablement évoquées,il est parfois nécessaire d'avoir une transformation de données en temps réel et dans ce cas l'ETL est bien placés et non spécialement conçue pour répondre a ces besoins.
*Support des anciens applications
Souvent,quand une organisation migrent à des nouvelles applications avec de nouvelles technologies,ces anciens applications reste toujours supportée avant d'être remplacée.
Le but de l'ETL c'est de transformer le « buckup » de ces données et mettre un pont entre ces deux systèmes, en veillant à ce que les données sont bien structurées et présentée comme nécessité pour tous les systèmes en liaison.
*Chargement des données au départ
On migrant à des nouveaux système les ETL offrent un environnement homogène de manipulation de données entre les anciens et les nouveaux système.
*Solution multi-vendeurs
De nombreuses organisations utilisent des solutions qui dépasse plusieurs limites vendeur d'où l'exigence que les données soient partagées entre plusieurs systèmes.
*Partage de données
beaucoup d'organisations ont besoin de partager leurs données avec beaucoup d'autres organisation ( fournisseurs, clients, partenaires d'affaires,....etc).
L ' Outils ETL assurer que le partage de données entre ces différents
systèmes se produit facilement et avec précision
*Qualité d'assurance
Ce qui n'est pas couramment considérée comme une fonction ETL, mais il est souvent plus facile d'avoir un ETL comme outil de validation des données et de correction des problèmes avant qu'ils soient acheminées vers de nouveaux système.
*Lecture Direct
Fournir une interface unifiée afin que les applications peuvent directement accéder à des données hétérogènes qui doivent être intéropèrable.
Ici, le "T" (Transform) en ETL peut être extrêmement précieux en tant que applications exigent généralement que les données sont présentées dans un schéma ou vue spécifique avant de l'avoir utiliser.
Comme indiqué plus haut, Les SIM / SGBD constituent la destination de données et les ETL n'est rien d'autre que de canaux par lesquels les données se déplace.
*Les quatre use cases ETL
La fonction d'ETL peut se résumer avec les 4 « Use case »suivants:
obtenir les données correctes,aux systèmes correctes dans des structures correctes dans un temps correcte.
Si on examine ça à tour de rôle:
-Données correctes:
L'outil ETL doit être en mesure d'accéder aux données d'une grande variété de systèmes. En effet, la récupération correcte de données est susceptible d'avoir besoin de données provenant de multiples systèmes pour satisfaire un seul outil ETL.
-Systèmes correctes:
L'outil ETL doit être capable d'écrire des données sur de nombreux systèmes différents en une seule opération ETL ,ce que pourrait exiger que plusieurs systèmes sont mis à jour en une seule opération.
-Structures correctes:
L'outil ETL doit être en mesure de restructurer les données de sorte que quand ils est prévu de leurs faire passer au système de destination, ils serons directement utilisable par les applications qui luis ont besoin. c'est tous simplement le « dumping », des données dans le «bon système», ou les applications nécessitant que le système fonctionne dans un seul « Job » qui englobe la préparation de données et la préparation de toutes considérations ETL.
Les outils ETL doivent être en mesure d'effectuer des opérations comme la préparation d'un schéma de « mapping » des données, calculs, et d'autres types d'opérations de restructuration et de sélection.
-Temps correctes:
L'outil ETL doit être efficace et capable de tourner en mode « batch » ou dans le cadre de certains opérations « scheduled/triggered » C'est là que l'ETL devient partie d'un système au lieu d'être utilisés tous simplement pour faire migrer les données d'un système à un autre.
Pour certains systèmes, l'accès direct est le seul moyen de fournir des données dans un temps correcte.
Il existe deux technologies complémentaires dans le domaine de traitements de données géographique et spatiales, les Systèmes d'information géographiques (SIG) qui sont les outils de traitement de données géographiques et les ETL spatiales qui publies et rends les données disponibles pour un "SIG".
Bien que les SIG existaient depuis plusieurs décennies, l'outils ETL n'a vue l'âge que maintenant en raison de volume importants de données géographiques qui les recueillies et les distribuent sous plusieurs formats concernés.
Les besoins d'utiliser un système d'information géographique dans les entreprises augmentent de plus en plus ce qui accélère l'utilisation de SIG par les spécialistes de grands projets de développement et d'aide à la décision.
Afin que les SIG peuvent effectivement utiliser des données et toutefois ils doivent êtres intéroperables avec ces données,l'interopérabilités qui peut être réalisée soit par transformation format-à-format ou par lecture directe,cependant le rôle de l'outil ETL spatiale est de mettre en disposition les données aux applications SIG.
Pour mieux comprendre le rôle inter-complémentaire de ces deux technologies, nous devons examiner le monde non-spatiales de systèmes d'information et management d'entreprise (SIM) et le rôle qui joue l' ETL dans ce domaine.
Qu'est ce que un ETL ?
ETL est l'acronyme de « Extract-Transforme-Load ».
Un ETL permet l'extraction, la transformation et le chargement de données depuis des sources diverses (Base de données,Fichiers,Flux,Webservice) vers des cibles préalablement définies par l'utilisateur.

De nombreux systémes de gestion de base de données sont supportés nativement en lecture/écriture (Oracle,Postgres/SQL,Ms Sql Server,DB,Mysql,.......).
De nombreux types de fichiers aussi peuvent egalement être lus ou écrits : Csv,EXEL,Txt,Xml,.....
Notons que la plupart des ETL disposent d'une interface graphique permettant l'élaboration des différents scénarios d'intégration.
Les rôles des Intégrateurs est ainsi quasiment facilitées,tant au niveau de la conception que de la l'intégration de traitement de données.
Bien que les ETL pour les traitements non-spatiales de données existent depuis un certain temps, l'outils ETL capables de gérer les caractéristiques des données spatiales a seulement apparu au début des années 1990.
Qu'est ce que un ETL Spatial?
les ETL Spatiales ont vue le jour dans l'industrie de SIG pour permettre l'interopérabilité (ou l'échange d'informations) dans l'industrie du large éventail d'applications de cartographie et des formats propriétaires. Toutefois, les ETL Spatiales sont également en train de devenir de plus en plus utilisée dans le domaine de systèmes d'information géographique et de management d'entreprise ainsi que pour aider a l'organisation et à l'intégreration des données spatiales et non spatiales, voire aussi le développement de la compétitivité stratégique d'affaires des ces
entreprises.

Traditionnellement, les applications a base de SIG ont des capacités de lire ou d'importer un nombre limité de formats de données spatiales, avec des librairies spécialisée dans la transformation des données,ou leurs concept est d'importer les données puis d'effectuer étape par étape de transformation et d'analyse dans l'application SIG lui-même, en revanche, l'ETL Spatial ne nécessite pas d'importer ou d'afficher les données seulement mais généralement de s'acquitter de ses tâches dans un unique processus d'extraction,transformation et chargement préalablement définis.
Avec les efforts visant à une plus grande interopérabilité au sein de l'industrie des SIG, de nombreuses applications SIG sont désormais intégrer des outils ETL spatiale au sein de leurs produits,notons l'interopérabilité des données par l'extension FME d' ArcGIS qui est un bon exemple de cela.
A quels usages et à quels utilisateurs répond un ETL spatial ?
1.Usages
Un ETL spatiale a un certain nombre d'utilisations qui est en faite:
- Nettoyage de données: L'élimination des erreurs dans un jeu de données.
- Fusion de données: Le regroupement de plusieurs jeux de données dans un cadre commun
le «common framework - Conflation» ou bien l'acte de combiner deux cartes dans une nouvelle carte qui est généralement effectué par l'enregistrement d'une zone de chevauchement entre le deux cartes est un bon exemple de celui la.
- Vérification des données: La comparaison de plusieurs jeux de données pour la vérification et l'assurance de qualité.
- La traduction de données: La conversion des données spatiales d'un format à un autre sans changement de structure ou de schéma.
2.Utilisations
Les ETL spatiales peuvent être utilisées dans plusieurs domaine d'organisation dans laquelle l'information géographique est une élément crucial de système d'information.
* Gouvernement
Les options sont pratiquement illimitées pour les gouvernements où la technologie spatiale permet a l'accès, le partage et la visualisation des données relatives aux personnes, lieux et services administratives.
L'analyse spatiale joue un rôle critique dans des domaines tels que la sécurité publique, développement économique, registres fonciers, les services de santé, la sécurité,la défense et le renseignement.
*Assurances
Le secteur des assurances profite de données spatiales. Par exemple, pour traiter les revendications, d'analyse spatiale, qui permet les réclamations pour localiser les transformateurs et les créances clients, de visualiser les zones de dommages, et de créer des cartes incident frontière.
Pour la souscription, les compagnies d'assurance utilisent l'analyse spatiale pour décider quels risques à assurer et à quel taux par l'identification des domaines de pointe potentiel de perte, de la cartographie historique des modes de revendications et de la segmentation à haut risque politiques, par région géographique.
*Institutions Financières
La technologie SIG offre un aperçu aux institutions financières sur leurs clients d'achat fidéles, les comportements financiers, et les besoins d'autres produits ou services qui lui ont permis de cibler leurs meilleures perspectives.
Les institutions financières utilisation des données spatiales pour la prospection du site pour déterminer l'emplacement des nouvelles succursales de banques et des guichets automatiques ainsi pour traiter les règlements fédéraux comme la loyauté des prêts au sein de la branche des zones où des données spatiales par la suite ils peuvent afficher la répartition des titulaires de comptes en ce qui concerne les entourant la démographie et la situation économique.
*Télécommunications/Location-Based Services (LBS)
Les Solutions ETL Spatiales fournis une technologie stratégique essentielle pour de nombreux fournisseurs d'information. Par exemple, les prestataires peuvent intégrer leurs données spatiales aux entreprises pour permettre aux personnelles d'avoir des informations d'assistance a distant , via téléphones cellulaires ou ordinateurs portables pour trouver les magasins ciblés et effectuer rapidement le suivi de produits, la numérisation et d'autres « Location Based Services »,exemple : les centres d'appels d'urgence qui alerte les centres de service d'accidents avec les endroits approprié au mieux d'intervenir rapidement et efficacement.
Système d' Informations Management et ETL
Avec l'augmentation de niveau d'utilisation de système d'informations et Management d'entreprise, les ETL ont connue la vie par les matures producteurs de « Business Intelligence » comme Informatica,Peravasive software,IBM,Oracle et Talend, ces outils donnent énormément d'avantages au système d'information et management d'entreprise.
Cependant avec cette analogie promu par ces canaux d'informations la connection de deux systèmes peuvent être bien assurée.
*Transformations de formats
ces canaux d'information sont utilisée pour changer les données d'une ou plusieurs formats d'un entrepôt de données source à une ou plusieurs formats d'un entrepôt de données destinations.
Ces entrepôts sont des jeux de données dans un système et une forme particulière.
Une fois l'entrepôt de données destination est remplis, le système sera accomplis.
*Accès directe
Ces canaux d'information sont utilisées pour la traduction directe d'une ou plusieurs données d'un entrepôts de données sources vers une ou plusieurs autres données d'un entrepôts de données destinations et dont il y' on a besoin.
Avec ces deux modes préalablement évoquées,il est parfois nécessaire d'avoir une transformation de données en temps réel et dans ce cas l'ETL est bien placés et non spécialement conçue pour répondre a ces besoins.
*Support des anciens applications
Souvent,quand une organisation migrent à des nouvelles applications avec de nouvelles technologies,ces anciens applications reste toujours supportée avant d'être remplacée.
Le but de l'ETL c'est de transformer le « buckup » de ces données et mettre un pont entre ces deux systèmes, en veillant à ce que les données sont bien structurées et présentée comme nécessité pour tous les systèmes en liaison.
*Chargement des données au départ
On migrant à des nouveaux système les ETL offrent un environnement homogène de manipulation de données entre les anciens et les nouveaux système.
*Solution multi-vendeurs
De nombreuses organisations utilisent des solutions qui dépasse plusieurs limites vendeur d'où l'exigence que les données soient partagées entre plusieurs systèmes.
*Partage de données
beaucoup d'organisations ont besoin de partager leurs données avec beaucoup d'autres organisation ( fournisseurs, clients, partenaires d'affaires,....etc).
L ' Outils ETL assurer que le partage de données entre ces différents
systèmes se produit facilement et avec précision
*Qualité d'assurance
Ce qui n'est pas couramment considérée comme une fonction ETL, mais il est souvent plus facile d'avoir un ETL comme outil de validation des données et de correction des problèmes avant qu'ils soient acheminées vers de nouveaux système.
*Lecture Direct
Fournir une interface unifiée afin que les applications peuvent directement accéder à des données hétérogènes qui doivent être intéropèrable.
Ici, le "T" (Transform) en ETL peut être extrêmement précieux en tant que applications exigent généralement que les données sont présentées dans un schéma ou vue spécifique avant de l'avoir utiliser.
Comme indiqué plus haut, Les SIM / SGBD constituent la destination de données et les ETL n'est rien d'autre que de canaux par lesquels les données se déplace.
*Les quatre use cases ETL
La fonction d'ETL peut se résumer avec les 4 « Use case »suivants:
obtenir les données correctes,aux systèmes correctes dans des structures correctes dans un temps correcte.
Si on examine ça à tour de rôle:
-Données correctes:
L'outil ETL doit être en mesure d'accéder aux données d'une grande variété de systèmes. En effet, la récupération correcte de données est susceptible d'avoir besoin de données provenant de multiples systèmes pour satisfaire un seul outil ETL.
-Systèmes correctes:
L'outil ETL doit être capable d'écrire des données sur de nombreux systèmes différents en une seule opération ETL ,ce que pourrait exiger que plusieurs systèmes sont mis à jour en une seule opération.
-Structures correctes:
L'outil ETL doit être en mesure de restructurer les données de sorte que quand ils est prévu de leurs faire passer au système de destination, ils serons directement utilisable par les applications qui luis ont besoin. c'est tous simplement le « dumping », des données dans le «bon système», ou les applications nécessitant que le système fonctionne dans un seul « Job » qui englobe la préparation de données et la préparation de toutes considérations ETL.
Les outils ETL doivent être en mesure d'effectuer des opérations comme la préparation d'un schéma de « mapping » des données, calculs, et d'autres types d'opérations de restructuration et de sélection.
-Temps correctes:
L'outil ETL doit être efficace et capable de tourner en mode « batch » ou dans le cadre de certains opérations « scheduled/triggered » C'est là que l'ETL devient partie d'un système au lieu d'être utilisés tous simplement pour faire migrer les données d'un système à un autre.
Pour certains systèmes, l'accès direct est le seul moyen de fournir des données dans un temps correcte.
mardi 24 février 2009
Committer on SpatialDataIntegrator
Spatial Data Integrator (SDI) is an ETL tool with geospatial capabilities. Based on Talend Open Studio, Talend's generic ETL solution, it includes specific geospatial components, all developed by Camptocamp.
Likewise regular TOS components, there are basically three sorts of Geo components: input, output and transform components. Input and output components read features from and write feature to datastores, respectively. Transform components read features from their input flows, possibly transform those features, and write features to their output flows. The term transform is to be taken loosely here as it represents any sort of operation.
Likewise regular TOS components, there are basically three sorts of Geo components: input, output and transform components. Input and output components read features from and write feature to datastores, respectively. Transform components read features from their input flows, possibly transform those features, and write features to their output flows. The term transform is to be taken loosely here as it represents any sort of operation.
Malek and Talend component
Talend Exchange is the place where Talend community can share items related to Talend opensource products, such as Talend Open Studio and Talend Open Profiler. Contribution is open to any user, no specific validation is needed,me also I havedevelopped one of most popular component the tJython component how implemente the high-level, dynamic, object-oriented language Python written in 100% Pure Java(Jython),It allows you to run Python on Talend.
The Open source Spatial Flex: OpenScales
OpenScales is a user-friendly and fast interface designed to manipulate spatial data : geographic raster viewing, data-vector editing, management of smooth transitions between scales and positions, ...
As a free open source and extensible tool written in ActionScript, OpenScales is designed to be easily plugged in your Flex or Air application. OpenScales is a small but powerful core of GIS
vendredi 14 décembre 2007
Baroudi Malek géomaticien Tunisien,Développeur SIG
Mon domaine de travail est l'open source et les systèmes d'informations géographiques libres.
J'ai l'honneur de travailler avec des collègues sur les domaines des SIG,et ERP (libre).
Le développement des nouvelles technologies de l'information permet aujourd'hui de créer de nouveaux besoins et de conquérir de nouveaux marchés. Mon objectif est d'acquérir une compétence pratique et une connaissance sur les systèmes SIG,manipulation GPS,GPRS...
Développer des solutions d’aide à la décision complète intégrant la gestion de flotte et la surveillance en temps réel des mobiles.
J'ai l'honneur de travailler avec des collègues sur les domaines des SIG,et ERP (libre).
Le développement des nouvelles technologies de l'information permet aujourd'hui de créer de nouveaux besoins et de conquérir de nouveaux marchés. Mon objectif est d'acquérir une compétence pratique et une connaissance sur les systèmes SIG,manipulation GPS,GPRS...
Développer des solutions d’aide à la décision complète intégrant la gestion de flotte et la surveillance en temps réel des mobiles.
Inscription à :
Commentaires (Atom)
Talend Certified
 Certification is awarded to individuals who successfully complete a comprehensive online test covering all aspects of the use of Talend Open Studio in real-life situations. Clients trusting a systems integrator to implement a solution want to be reassured that the consultants are indeed experts in the technology. Talend certification gives them this level of assurance.
Certification is awarded to individuals who successfully complete a comprehensive online test covering all aspects of the use of Talend Open Studio in real-life situations. Clients trusting a systems integrator to implement a solution want to be reassured that the consultants are indeed experts in the technology. Talend certification gives them this level of assurance.
Mission Topographique

Promo6 Mastére Géomatique
Le Groupe CLLFST

SFD 2007
CLLFST & INFO+

SFD 2007